让神经网络会做唐诗
黑云知旧柳,时日万年春
杨柳秋云雪,光微欲满霜
相随无寂寞,出国自曾之
不是诸侯客,今朝忆白头
今年早些时候,受到Karpathy的《不可思议的神经网络》启发,我训练出了一个能做近体唐诗的神经网络。具体效果如何请各位看官移步到这个展示页面上面来自行鉴赏。代码已经放在Github上面。
神经网络(Neural Network)最近被吹捧的很厉害。各大公司们觉得好像找到了一个解决无数问题的方法,学术界觉得找到了一个能让自己论文数量翻倍的利器。它目前应用在图像和语言方面的效果非常好,原因有两个:
- 传统的机器学习方法都是建立在统计的基础上,但是当数据与数据之间的关系难以用统计来描述的时候传统方法就无能为力了。
- 传统的机器学习很多时候需要专家的知识来挑选特征(feature),特征的好坏跟学习成果有很大的关系。
但是很多时候程序员们并不是绘画、语言学、古典文学或者X光片诊断专家,挑出来的特征效果往往不好。往往就算是专家,因为人的学习过程跟程序的学习过程不同,可能同样的特征还是没有用。
神经网络的厉害之处就在于它克服了以上两个难点。一是神经网络里面每一个神经元都有非线性的公式,有办法抓取复杂的难以用数学公式描述的关系。二是最近几年大家经常在媒体上面见到的一些做语音识别,图像识别的网络,它们训练的时候都是原始数据输入,到结果直接输出的模型(End to End)。对于程序员来说这是一个福音,因为他们现在并不需要在某个领域成为专家就能做一些非常好玩实用的程序。就拿这个作诗的模型作为例子。我以前中学的时候成天语文不及格,一度以为自己再接着写作文就要给中国文学丢脸了。现在这个作诗程序写出来的诗比我写得好,靠的并不是我对唐诗的研究,而是它在经过翻阅了40314首近体诗之后自己总结出来的规律。
但是即便如此,简单的神经网络也是有局限性的。你可以发现在Karpathy原文里面的例子中,虽然他的莎翁、学术论文乍看都有点像,但是如果仔细都下去就会发现经常前后牛头不对马嘴。这个是受到时间递归神经网络(Recurrent Neural Network,以下都叫RNN)本身限制所致。
具体原因就是RNN的使用时候的结构,可以参照下面这张图。
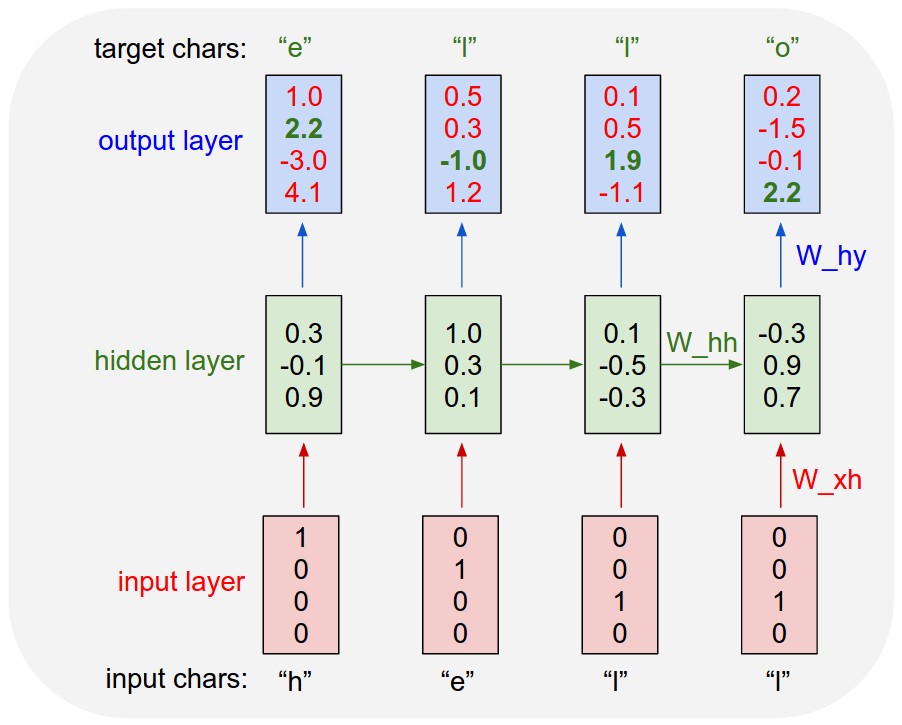 来源:Andrej Karpathy
来源:Andrej Karpathy
每一次的输出会被当作下一次的输入又返还到神经网络里面去。训练这个神经网络就是把这个过程逆向,从最后的输出开始往之前的输出推,每一次推的时候要用到当时的输入和输出计算梯度(gradient)。虽然理论上说,神经网络输出第1个字符时候的状态会影响到第1000个字符,但是在实际运用当中如果你当真把第1000个字符的梯度退回到第1个时间状态,就会有两个问题
1.需要储存999个中间值,这些中间值很快就会吃光你的内存。 2.Vanishing/Exploding Gradient, 太远的gradient可能就太大爆掉,或者太小对神经网络完全没有影响
所以在Karpathy的例子里面他用了默认100个英文字母,所以出来的结果就是神经网络到后面的时候就会忘记自己在前面说了什么。虽然能够学到词的拼写和其前后关系,但是一个段落里面的逻辑关系就无能为力。
近体诗的几个特点反倒让这个神经网络非常适合。这里所说的近体诗就是五言和七言的律诗、绝句。
一个是字数有限。近体诗最长的就是七律,加上标点符号总共就才64个字符。一个能记住30个字符的神经网络轻松能利用之前记住的半首诗来推断下一个字是什么。
二是句式固定。五言七言两种结构简单明了,单数距逗号结尾,偶数句句号结尾。神经网络不需要花太多功夫就能记住这个规律。
三是规律明确。因为近体诗对平仄对仗的要求,每一句选字都跟上一句相对应的字有一定的联系。神经网络有足够多的参照例句来学习这个对应关系。
把训练这个网络的成本大概列一下,给同样想训练自己的神经网络的同学们参考。今后如果大家碰到类似的问题,不妨用RNN试试。
- 大概$150的AWS的GPU 节点使用费,和一些其他忽略不计的数据处理的各种CPU节点。
- 一周收集并清理全唐诗。
- 然后训练的时候走了很多弯路,最后这个model在一个月之后才弄出来的。
- 处理平仄花了一周。
最后还是希望大家能接着发扬中国传统文化,少走程序员的歪门邪道,真正学会写唐诗。
以下是技术细节,想玩神经网络的人可以看一看。
#####整个训练中最大的敌人就是GPU的显存限制。 训练的时候做的每做一件事都要看显存的脸色,在AWS上面用只有4G显存的K40非常让人恼火。通常情况下越大的网络就能学到更多的东西。但是也会很快的碰到内存耗尽的错误。折衷的办法有,但是非常少。
- 降低每批次样本量(batch size)。这个会增加训练时间,省出来的内存并不多。我就没用。
- 降低网络神经元数量。这个虽然减少训练时间,不过是以精度为代价的,所以这个应该是最后才用的手段。
- 半精度浮点,不过好像是因为Torch里面还没有实现,没有找到相应的API。
- 在训练全唐诗的时候还可以降低字典大小,这个不光增加了常用字的精度,也减少了内存占用量。这个办法比较推荐。第三节会详细描述。
#####LSTM与RNN的对比
RNN有两个著名的衍生姐妹,Gated Recurrent Unit和Long-Short-Term Memory。两个的模块图都非常复杂,箭头飞来飞去,我也看的不是太懂。就连斯坦福的Richard Socher在上课的时候都说现在没有一个LSTM的模块图是即容易看懂又完全正确的,他也没辙,就画了这么一个盒子。
 来源:Richard Socher
在Karparthy当时发布他的代码的时候好像GRU和RNN都有一些问题,就只有LSTM能工作。所以后来我又从网上另外找了个Element Research的RNN放进去。理论上来说LSTM的优势在于它在“该忘记过去”的时候能“忘记过去”。但是我能注意到的差别就是RNN的训练时间较短,但是错误率却降不下去,没有什么用。LSTM训练时间长很多,但是最后效果好不少。
来源:Richard Socher
在Karparthy当时发布他的代码的时候好像GRU和RNN都有一些问题,就只有LSTM能工作。所以后来我又从网上另外找了个Element Research的RNN放进去。理论上来说LSTM的优势在于它在“该忘记过去”的时候能“忘记过去”。但是我能注意到的差别就是RNN的训练时间较短,但是错误率却降不下去,没有什么用。LSTM训练时间长很多,但是最后效果好不少。
#####Word Embedding的重要性,以及词典的大小 在神经网络里面每一输入输出最后都是向量或者矩阵。所以为了把所有的字都能转化成向量,用到的一个技巧就是embedding。每一个字变成一个独特的向量,里面只能有一个1。举个例子,我现在有5个字:我,爱,赋,唐,诗。
这五个字分别变成[1 0 0 0 0], [0 1 0 0 0]等等,作为神经网络的输入。所以当输入的数据里面有3000个不同字符的时候这个向量就会是2999个0和1个1。
神经网络的第一层实现的功能就是把这个很长的one hot vector变成一个独特的长度更低的向量。
因为全唐诗里面用到了5828个不同的字,如果全部都放到字典里面的话显存马上就被吃光了。而且一些出现次数较少的字神经网络缺乏足够多的数据去学习它的意义,所以在实际使用的时候我只取了出现频率最高的2000个字,用34%的独立字符覆盖了94.56%的总体字数。剩下的都用一个*代过了。
按道理来说如果有实现训练好的类似word2vec的语言模型效果应该会好很多。可是我也没有那么多钱去租机器和收集现在网络上所有的中文数据,估计只有百度这种规模的公司才有足够的数据和资源来做了。
#####加入起始和终止字符,让结构更加明确
神经网络并没有办法知道哪里是诗的开头和结尾,这样训练出来的模型经常会只给你半首诗然后就“分心”了。我在输入的每一个开头放了一个^,结尾放了个$,神经网络就能输出完整的诗了。
#####利用Dropout增加准确率 Dropout的意思就是在训练的时候一定数量内部的神经元会被随机的设置为零,但是训练完了之后把他们回复原状。可以想象一个小孩学习如何识别一辆车,她每次只能看到不同的车的部分,而不是每次都看整辆车。根据生活经验训练出来的小孩你最后给她一张完整的汽车图她肯定也会告诉你这是汽车。Dropout就是在训练的过程中遮挡一部分特征。为什么这样做能增加神经网络的准确率还是一个正在被研究的问题。 我尝试过0,0.2,0.5三个值,最后0.2给出来的结果最好。
#####用不同的SGD方法效果并不明显 Torch里面带了不少做Gradient Descent的变种,不过我试了几个好像区别不大。Karpathy的代码里面默认就是RMSprop。他的解释是
I like to use RMSProp (a per-parameter adaptive learning rate) to stablilize the updates.
#####生成的字符表是一个概率分布 最后解释一下这个神经网络的生成结构。神经网络每次在做预测的时候并不是给出某一个字符,而是给出一个整个字典里面所有字可能出现的概率。
例如如果我用“月”字打头的时候,每当神经网络需要生成下一个字符时,神经网络就会产生的概率表。每一行代表一个字,例如第一行就是“月”后面的第一个字,“人”出现的概率是4%,“山”出现的概率是3%,不过最后随机抽样的结果是“如”。接下来“如”字后面更有可能出现“不”,“如不”, 听上去想是一个像样的词,不过因为程序在随机抽样,“红”字最终当选。这里列举的每一行只包括概率最高的几个候选字符,概率更低的字被省略了。如果你仔细看就会发现神经网络已经学到了唐诗里面的高频词,如“千里”, “江上”, “平生”。 值得注意的就是当“,”或者“。”出现的时候他们的概率都是80%以上,这也能说明神经网络已经知道在什么时候应该断句了。
如 人/0.04 山/0.03 无/0.01 ,/0.01 家/0.01 春/0.01 云/0.01
红 不/0.02 一/0.01 无/0.01 山/0.01 春/0.01 何/0.01 风/0.01
落 树/0.11 叶/0.11 草/0.06 下/0.04 雨/0.03 水/0.03 柳/0.03
来 不/0.02 日/0.01 水/0.01 一/0.01 满/0.01 夜/0.01 月/0.01
, ,/0.82 无/0.01 山/0.01 春/0.00 相/0.00 风/0.00 不/0.00
千 一/0.02 不/0.02 白/0.02 此/0.02 春/0.02 秋/0.01 风/0.01
里 里/0.86 古/0.02 载/0.02 事/0.01 岁/0.01 树/0.01 万/0.01
谢 不/0.03 一/0.02 独/0.02 白/0.02 见/0.01 向/0.01 有/0.01
平 江/0.05 公/0.05 君/0.04 山/0.04 人/0.03 家/0.03 天/0.02
君 生/0.12 州/0.06 城/0.05 山/0.04 阳/0.03 门/0.02 家/0.02
。 。/0.97 $/0.03 ,/0.00 人/0.00 不/0.00 相/0.00 此/0.00
江 白/0.03 不/0.02 一/0.02 日/0.02 野/0.02 夜/0.01 月/0.01
水 上/0.31 水/0.20 海/0.05 月/0.04 北/0.04 树/0.03 路/0.02
将 无/0.03 春/0.02 山/0.02 秋/0.02 千/0.02 云/0.02 连/0.02
这就是为什么你给同样的字打头,每次输出的诗内容却是不同的原因。
#####将平水韵作为神经网络的输出过滤
这个神经网络训练到最后关键的押韵效果并不好。因为就像上面说的,每次取字的时候它都在“抽牌”,很有可能就抽到不押韵的字。所以我把整个《平水韵》的字符表都放在程序里面作为最后过滤的一道工序。因为也不是每一个字在诗里面都要符合平仄的规律,所以我在诗需要平仄的地方把抽到但是不合理的字符规律的给去掉重新抽。所以最后平仄还是符合的。
但是如果要押韵的话就需要事先知道神经网络正在做的这首诗是律诗还是绝句,因为绝句和律诗韵脚的位置是不一样的。可惜在它作诗完成之前,我并不知道它会在什么时候截至,所以并不知道输出的是什么格式。最后韵脚这块还没有做。有一个办法就是拿已有的诗再重新填回到神经网络里面,然后在出该出韵脚的时候再加个韵脚过滤。
另一个更彻底的办法应该是把平仄和韵脚当成一个特征也作为神经网络的训练输入。这样应该不用额外再加后期处理。不过因为时间有限这还没有来得及实验。
感谢给这篇文章提供过建议和支持的人
Bolei Zhou, Shi Yan, Tao Cai, Yina Tang, Haocheng Qin